
VIRD: View-Invariant Representation through Dual-Axis Transformation for Cross-View Pose Estimation
Abstract
Accurate global localization is critical for autonomous driving and robotics, but GNSS-based approaches often degrade due to occlusion and multipath effects. As an emerging alternative, cross-view pose estimation predicts the 3-DoF camera pose corresponding to a ground-view image with respect to a geo-referenced satellite image. However, existing methods struggle to bridge the significant viewpoint gap between the ground and satellite views mainly due to limited spatial correspondences. We propose a novel cross-view pose estimation method that constructs view-invariant representations through dual-axis transformation (VIRD). VIRD first applies a polar transformation to the satellite view to facilitate horizontal correspondence, then uses context-enhanced positional attention on the ground and polar-transformed satellite features to mitigate vertical misalignment, explicitly bridging the viewpoint gap. To further strengthen view invariance, we introduce a view-reconstruction loss that encourages the derived representations to reconstruct the original and cross-view images. Experiments on the KITTI and VIGOR datasets demonstrate that VIRD outperforms the state-of-the-art methods without orientation priors, reducing median position and orientation errors by 50.7% and 76.5% on KITTI, and 18.0% and 46.8% on VIGOR, respectively.
Method
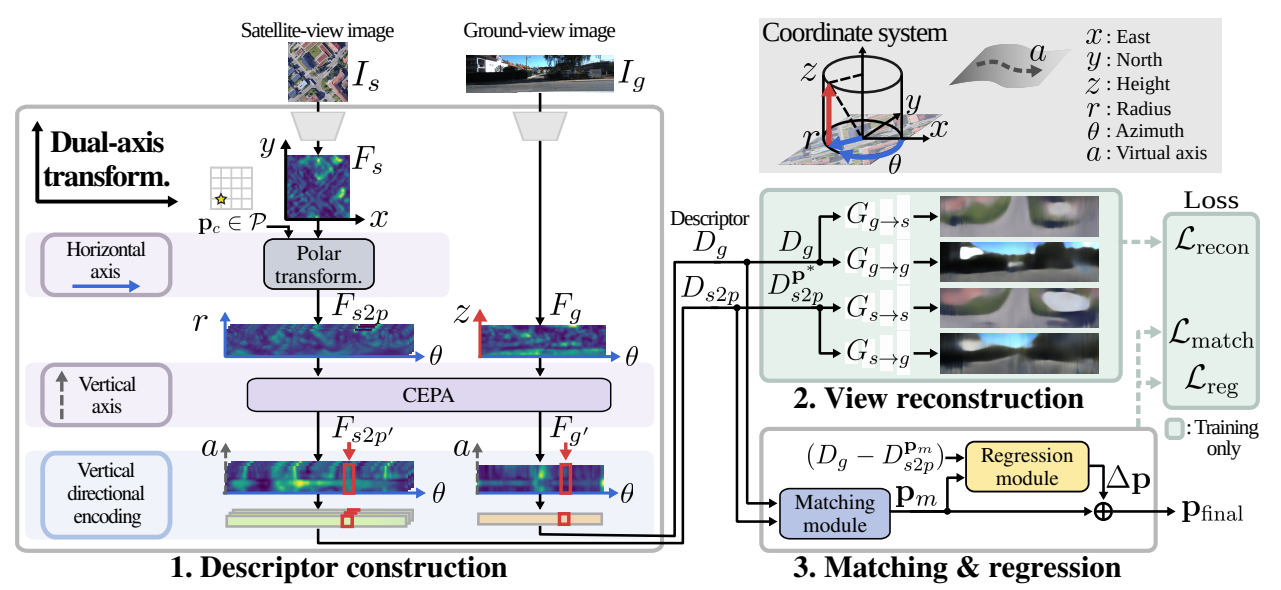
VIRD bridges the viewpoint gap between ground and satellite views by constructing view-invariant descriptors through three jointly optimized components.
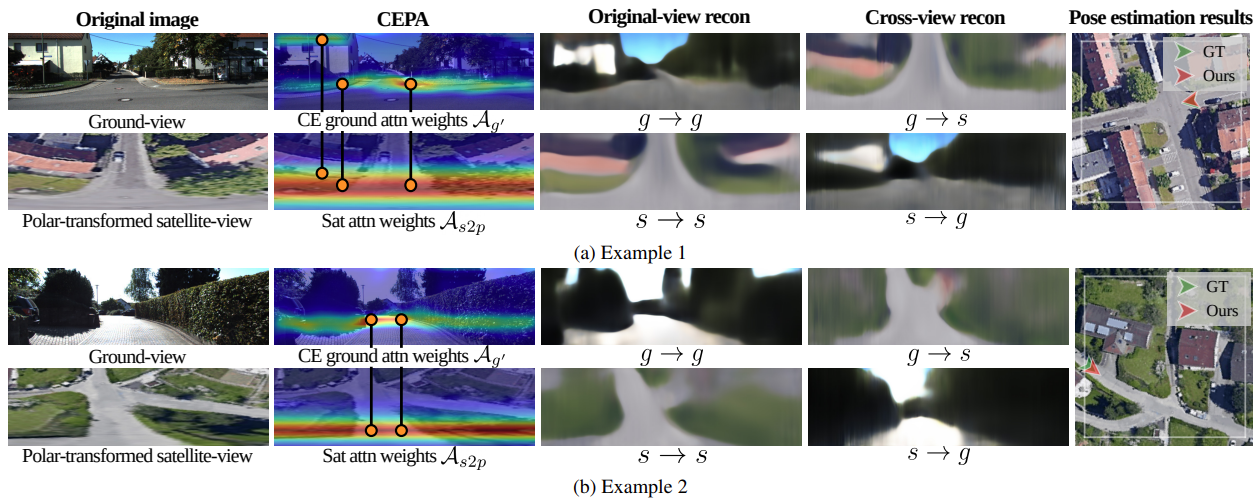
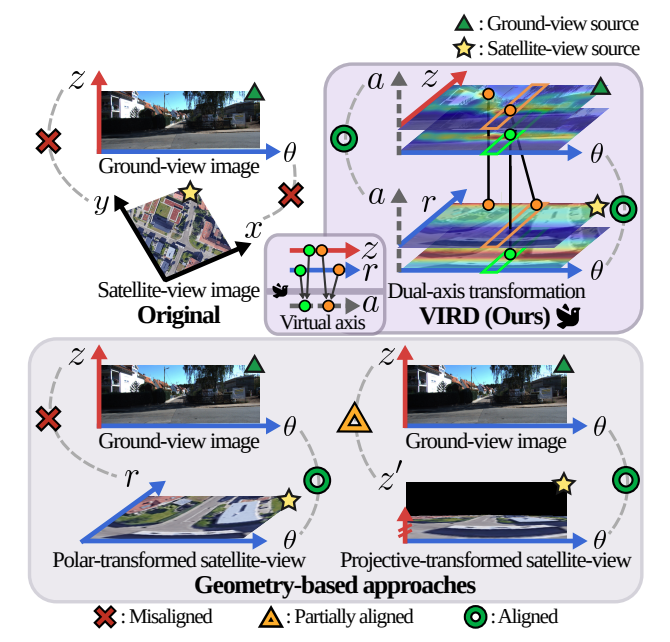
(1) Dual-axis transformation. The viewpoint gap occurs along both horizontal and vertical axes of the image plane. For the horizontal axis, VIRD applies a polar transformation to the satellite view, mapping the azimuth direction as the horizontal axis to establish consistent cross-view correspondence. The remaining vertical discrepancy is addressed by context-enhanced positional attention (CEPA), which transforms ground and polar-transformed satellite features along the vertical axis via positional attention. Unlike prior geometry-based approaches, CEPA learns a view-consistent vertical transformation without camera parameters and adaptively captures vertical structures in the ground view by leveraging contextual cues.
(2) View-reconstruction loss. To further strengthen view invariance, the descriptors are trained to reconstruct both original and cross-view images. This reconstruction loss encourages the representations to focus on spatial structures shared across views, rather than view-specific appearance.
(3) Matching and regression. A matching module computes cosine similarity between ground and candidate satellite descriptors to estimate a coarse pose. A regression module then refines this estimate by predicting residual pose offsets, yielding the final 3-DoF camera pose.
Results
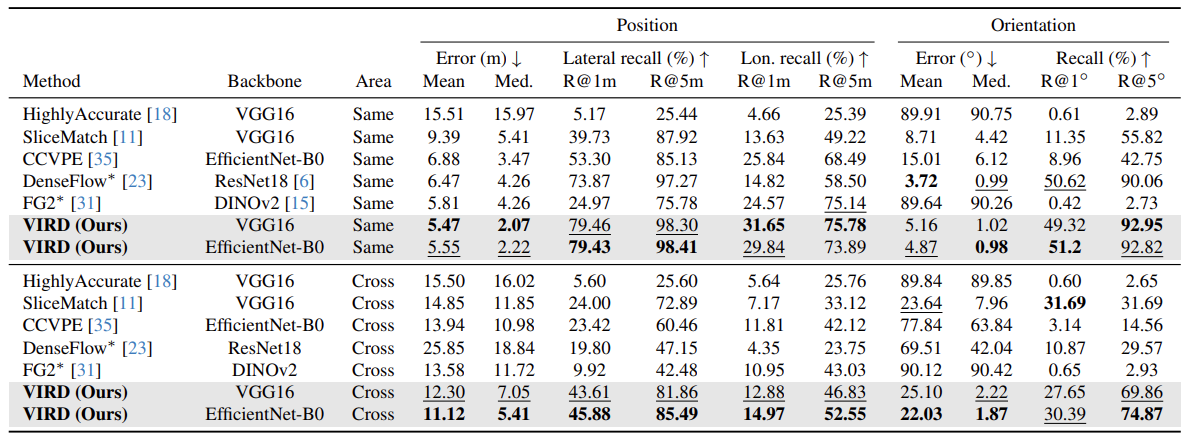
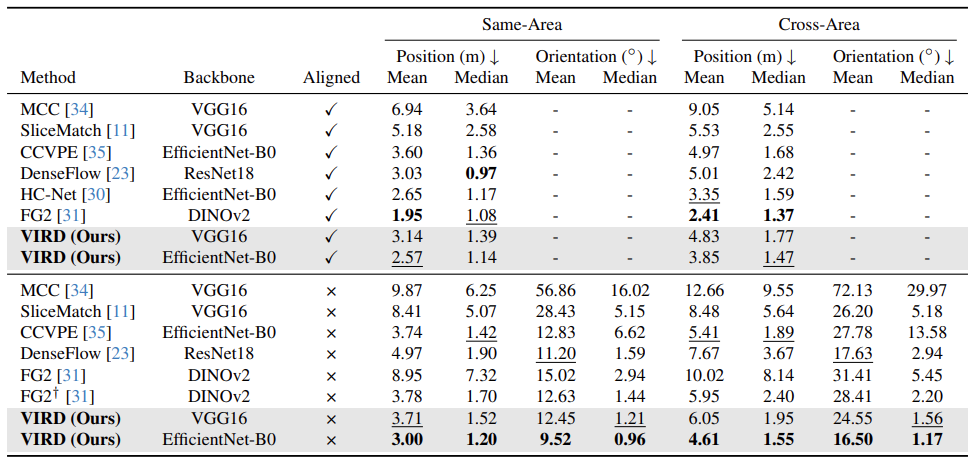
Reduction in median errors vs. state-of-the-art without orientation priors (EfficientNet-B0, cross-area setting).
Video
BibTeX
@inproceedings{park2026vird,
title = {VIRD: View-Invariant Representation through Dual-Axis Transformation for Cross-View Pose Estimation},
author = {Park, Juhye and Lee, Wooju and Hong, Dasol and Sung, Changki and Seo, Youngwoo and Kang, Dongwan and Myung, Hyun},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}